
Byte Latent Transformer
The Efficiency of Dynamic Byte Patching


We refer to the paper “Byte Latent Transformer: Patches Scale Better Than Tokens” by Meta (link).
Introduction
Byte Latent Transformer (BLT) is a novel architecture for large language models (LLMs) that processes raw byte data instead of relying on traditional tokenization: BLT encodes bytes into dynamically sized patches based on the entropy of the next byte (chopping is based on the detection of an unexpected change), which allows for flexible allocation of computational resources. This means that more resources are devoted to complex data while simpler data can be processed with fewer resources, leading to improved efficiency.
Most LLMs map text bytes into a fixed set of tokens; instead, BLT dynamically groups bytes into patches.
Patching: From Individual Bytes to Groups of Bytes
Formally, a patching function segments a sequence of bytes
of length n into a sequence of m < n patches
by mapping each xi to the set {0,1} where 1 indicates the start of a new patch. There are several patching functions such as Strided Patching Every K Bytes, Byte-Pair Encoding (BPE), Space Patching. BLT, however, uses Entropy Patching.
Entropy Patching: Using Next-Byte Entropies from a Small Byte LM
At first, a small byte-level auto-regressive language model on the training data for BLT is trained: this is needed to obtain probabilities p over the byte vocabulary V to compute entropies H(xi) for each byte xi.
Intuitively, high entropy represents a more chaotic or uncertain situation. Example: in word guessing, the entropy is initially high (with many possible words), but as more letters are revealed, the entropy decreases until only one word remains — the correct answer.
Patch boundaries are identified each time entropy levels are
(first method) higher than a certain global threshold θg or,
(second method) the difference in entropy of two consecutive bytes (actual and preceding) is higher than θ.
the following images are really explanatory (source).
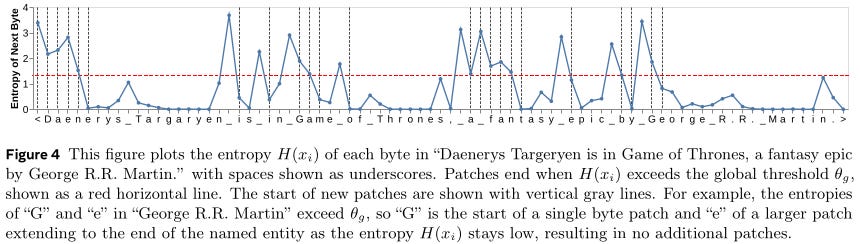

The last figure shows how patching schemes group bytes in different ways, each leading to a different number of resulting patches. Note the two entropy patching schemes in the middle. The last patching scheme represents patching on entropy using a small CNN byte-level model with 2-byte context.
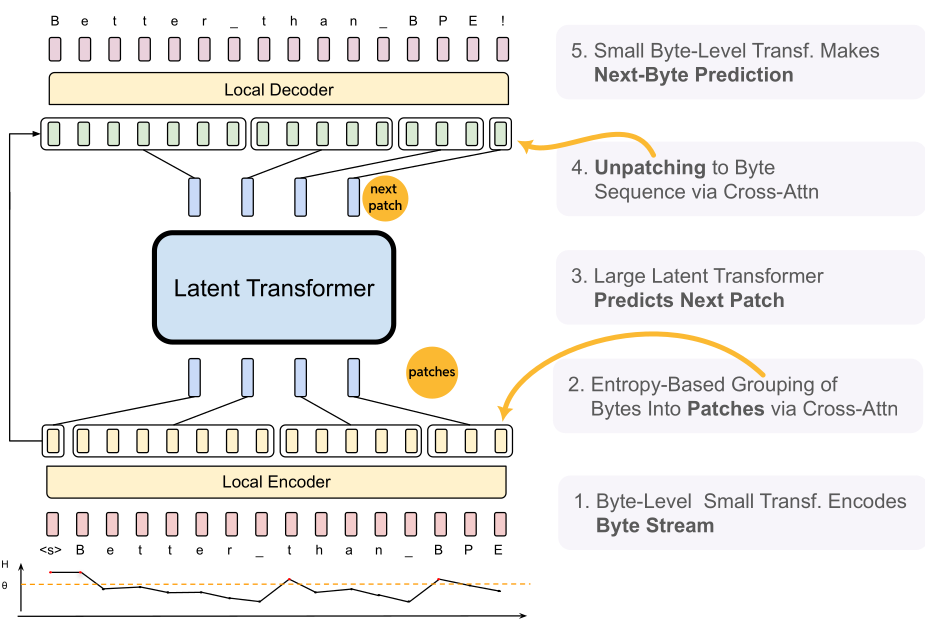
The BLT architecture
The BLT consists of three main components:
Local Encoder: Transforms input bytes into expressive patch representations using hash-based n-gram embeddings.
Latent Transformer: A larger model that processes these patch representations, optimizing computation through block-causal attention.
Local Decoder: Converts patch representations back into raw bytes, ensuring effective information flow between the encoder and decoder.
Check the figure below, adapted from the original paper.
BLT exhibits superior scaling properties by allowing simultaneous growth in both patch and model sizes without increasing training or inference costs. This is achieved through a FLOP-controlled scaling study, demonstrating that BLT can handle up to 8 billion parameters and 4 trillion training bytes effectively.
Performance Improvements
In the study, various compute-optimal BPE (Byte Pair Encoding) and BLT (Byte-Level Transformer) models on the Llama 2 dataset are trained across model sizes from 1B to 8B parameters. The models are trained with an optimal ratio of parameters to training data, as determined by Llama 3, to achieve the best performance within a given compute budget. The results show that BLT models either match or outperform BPE models. In particular, BLT can use larger patch sizes (e.g., 6–8 bytes) to achieve better scaling and reduce inference FLOPs (up to 50%) At larger model sizes, BLT with larger patch sizes surpasses BPE models in performance.
To further evaluate the scaling characteristics, an 8 billion parameter BLT model was trained beyond the compute-optimal ratio using the BLT-1T dataset, which is larger and of higher quality. Its performance was then assessed across a range of standard classification and generation benchmarks. A comparison of flop-matched BLT 8B models trained on the BLT-1T dataset, which includes high-quality text and code tokens from publicly available sources, against baseline models using the Llama 3 tokenizer shows that BLT outperforms Llama 3 on average. Additionally, depending on the patching scheme used, BLT models achieve notable reductions in flops with only a slight decrease in performance.
Furthrmore, BLT models can increase both model and patch sizes while maintaining the same training and inference flop budget. Larger patch sizes reduce compute usage, enabling growth in the latent transformer. A scaling study finds that BLT models outperform other tokenization-based models, especially with patch sizes of 6-8 bytes. Although BPE models perform better with small budgets, BLT models surpass them when compute-optimal limits are exceeded. Larger patch sizes and models improve performance, with BLT scaling better at larger sizes. The results highlight that BLT's patch-based architecture achieves better scaling trends, especially at larger model scales.
Conclusion
The Byte Latent Transformer offers a flexible and scalable alternative to traditional token-based models. Its ability to handle raw byte data dynamically makes it a promising solution for future language modeling challenges.
Useful links
Original BLT article (link)
BLT code (link)