


LLMs: a 5 mins trip
What Large Language Models actually do in mathematical terms

Large Language Models (LLMs) have revolutionized the way we interact with text, powering everything from chatbots to advanced translation systems. But beneath their impressive capabilities lies a rich mathematical foundation that drives their understanding and generation of language. In this quick math tour, we’ll explore the essential mathematical structure that underpin LLMs. Just an overview, without delving into details.
Discrete distributions
Think of a discrete distribution as a set of stems or spikes, as in the following picture, representing the probabilities related to some objects — in this case we represent how frequently the individual letters of the alphabet appear in English language texts.
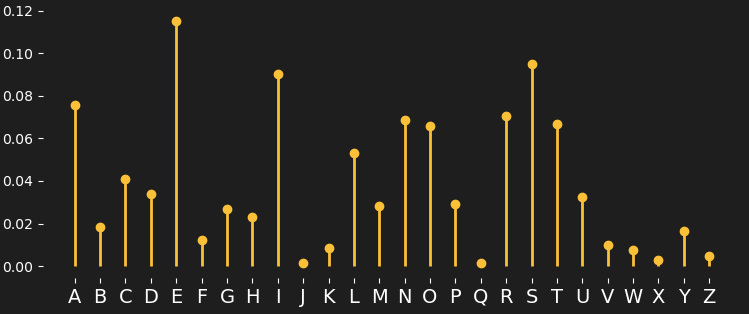
The letter “E” is the one with the highest frequency, so it has the greatest probability of appearing in a text. The sum of all the spike probabilities is 1. We can also choose a representation with squares (size = probability).

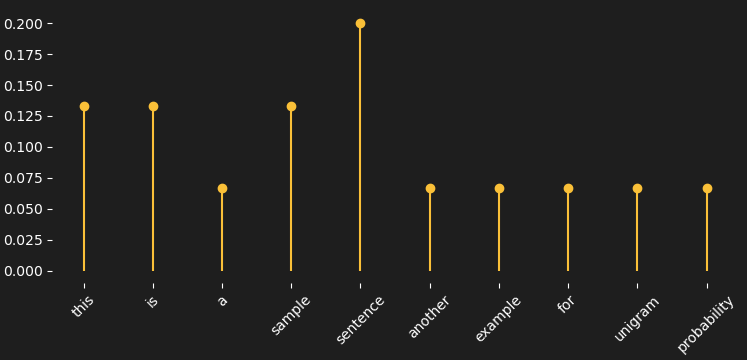
You can consider distributions over vocabularies. For example, consider the following toy corpus.
# Example - small corpus
corpus = [
"this is a sample sentence",
"this is another example sentence",
"sample sentence for unigram probability"
]The distribution associated to this simple example corpus is the following.
Large Language Model overview
Large Language Models (LLMs) are typically based on the Transformer architecture and employ an autoregressive approach. Autoregressive modeling in LLMs means that the model generates text one token at a time, predicting the next word based solely on the sequence of previously generated words, without looking ahead.
A token in natural language processing (NLP) is a unit of text that serves as a basic element for language models to process and understand language. The exact nature of a token can vary depending on the model and tokenization method used (for example, BPE). Enter some text on this page to see how tokenization works.
Input sentences or prompts are tokenized into a sequence of discrete tokens
where V is the vocabulary (the set of unique tokens — which can be words, subwords, or characters — that the model can recognize, understand, and generate during language processing).
The LLM processes x token by token to produce a sequence of logits
where S = |V | is the vocabulary size. Each logit vector ℓi is a very very long vector (one entry for each element in the vocabulary!) that represents the model’s prediction for the i-th token, given preceding tokens (from x1 to xi - 1).
These logits are not probabilities but scores that reflect the model's relative preference for each token before normalization. For each position i, applying the softmax function (softmax transforms the raw output scores into a probability distribution) to ℓi yields a probability distribution over the vocabulary:
The distribution p is represented by a long probability vector whose j-th entry is the probability of the j-th token being the next predicted token. There are various sampling methods to determine the final prediction for the next token; the arguably simplest approach, known as greedy sampling, selects the token with the highest probability yi .
For the last input token xn, the logits ℓn give the probability distribution
representing the likelihood of each token inV being the next token after x. Once we have done with the input sequence x, we will end up with a sampled output sequence
The probability distribution for generating the i-th token yi , conditional on input x and prior outputs y<i = ( y1 , . . . , yi-1 ), is
This distribution represents the model’s estimation of the next token based on the prompt and the sequence generated up to that point.
Example
A language model like GPT-2 takes tokens as input and predicts the next token. Conceptually, this prediction can be seen as a multi-class classification problem, where each class corresponds to a possible token—in GPT-2’s case, there are 50257 such classes. For instance, given the sentence
One, two,
GPT-2 processes the token IDs [3189, 11, 734, 11] and assigns a 39.71% probability to the next token ID being 1115, which represents the token “three”.

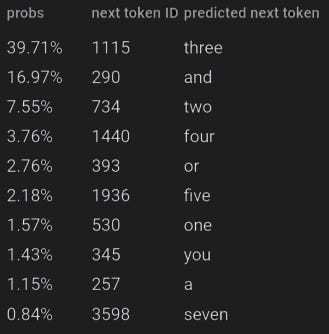
Here probs represents — essentially, up to percentages — distribution p( · | x1 , x2 , x3 , x4 ). You can find more about the preceding example here.
Conclusions
So, under the hood, LLMs are next token prediction models. This is a controversial truth, which tends to belittle AI and fuels disillusionment among those who idealize an artificial intelligence with real reasoning abilities. But there would be too much to discuss about the relationship between human intelligence and the internal mechanics of AI models, certainly much more than the limited space dedicated to a simple blog.