Reasoning without External Rewards
From self-certainty to Reinforcement Learning from Internal Feedback

This post is inspired by the paper “Learning to Reason without External Rewards“ by Zhao et al. (link).
Reinforcement learning has significantly improved large language models, initially through Reinforcement Learning from Human Feedback (RLHF) and more recently via Reinforcement Learning with Verifiable Rewards (RLVR) which uses automatic correctness checks.
RLHF depends heavily on human annotations, which are costly and can introduce biases. Instead of relying on reward models learned from human preferences, RLVR uses automatically verifiable signals as rewards. For example, in mathematical problem-solving, the reward can be a simple exact match between the model’s answer and the correct answer. This approach has been shown to enhance reasoning abilities in large language models. While RLHF is expensive and potentially biased, RLVR requires domain-specific verifiers and gold-standard solutions, limiting its broader use. These limitations motivate exploring more general, scalable reward approaches, raising the question of whether LLMs can enhance reasoning using only intrinsic, self-generated signals without external supervision.
Can large language models improve their reasoning skills by relying solely on intrinsic, self-generated signals rather than external human feedback or domain-specific verifiers?
Self-certainty: a new measure of confidence for LLMs
An LLM output distribution has its maximum randomness if it is uniform. In this case there is not much choice since all tokens are assigned the same probability. If we assume that higher confidence corresponds to output distributions further from a uniform distribution U — representing maximum uncertainty — then we find that KL divergence is effective in evaluating how much the predicted distribution deviates from randomness:
where p is the probability distribution over possible next tokens given some context — input prompt x and prior outputs y<i = ( y1 , . . . , yi-1 ). Applying the definition
Averaging the last KL divergence on the length of sequences, we define the self-certainty at sentence level:
In the next paragraph we will see how this measure can be applied to very recent language models.
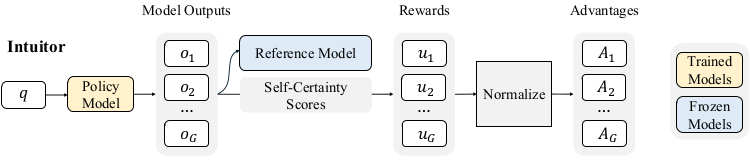
The Intuitor
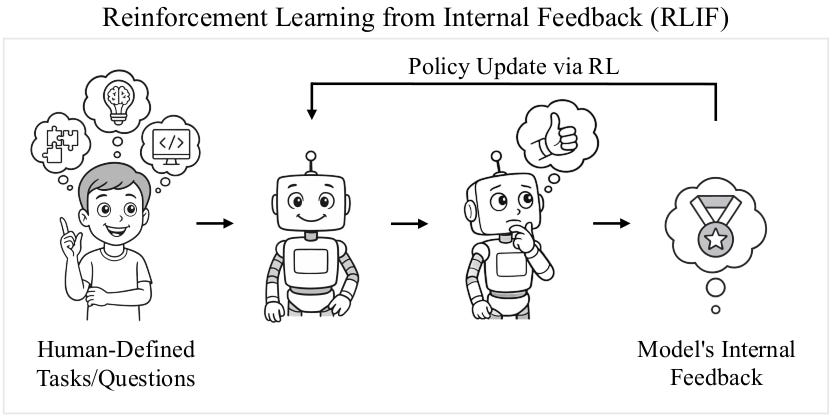
Reinforcement Learning from Internal Feedback (RLIF) is a new paradigm for training large language models (LLMs) that relies solely on intrinsic model-generated signals rather than external rewards or human annotations. Unlike traditional methods such as Reinforcement Learning from Human Feedback (RLHF), which require costly and labor-intensive external supervision, RLIF leverages internal reward proxies like self-certainty.
A major instantiation of RLIF is the Intuitor algorithm. Intuitor enables fully unsupervised training loops where LLMs assess and improve their own reasoning and outputs internally. In practice, Intuitor uses Group Relative Policy Optimization (GRPO) to fine-tune the model. Check this page for an easy GRPO introduction.
For each input query q, multiple candidate outputs oi are generated, each scored by their self-certainty values. These scores serve as relative rewards that estimate the advantage for policy updates. The policy is then optimized to increase the likelihood of producing outputs with higher self-certainty. Self-certainty assumes the following form:
The key innovation in Intuitor is replacing external rewards with self-certainty scores in GRPO’s advantage computation. Specifically, each output oi is scored by: